Pivotal Tracker
2026-04-19
If you ever think "I should sit down and make a plan", you need to use Pivotal Tracker. It is not an agile management and planing tool, it is common project management sense distilled.
Enough of the big praising words, I really think that Pivotal Tracker is the most sensible tool you can use to plan and track your project's progress. It praises itself with being agile and you will find terms such as "stories", "velocity", "backlog" and "iteration", but in it's essence it just works, no matter what you think about agile.
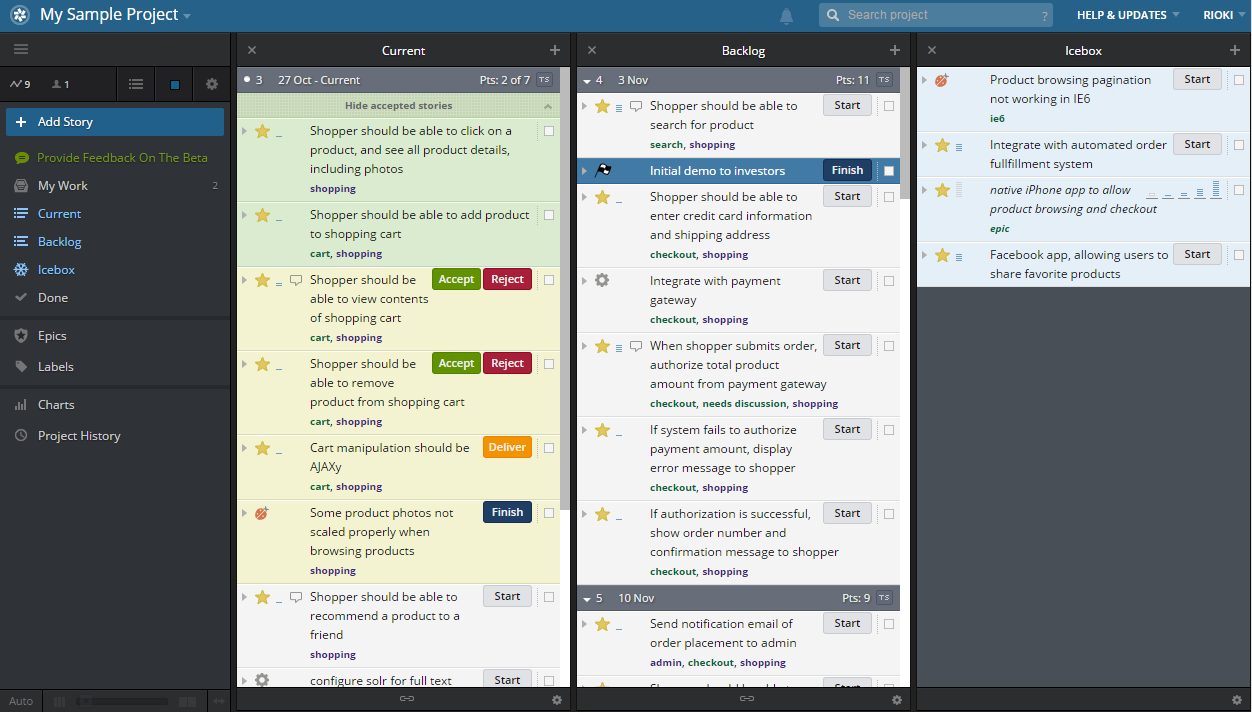
The interface is structured loosely on the kanban board concept. Although you can arrange the columns as you like, it comes with the above view. The stories "flow" right to left and rise to the top. This means that the most pressing item is on the top left, below the completed items.
In the "Current" column you see all this iteration's tasks, the "Backlog" are the scheduled tasks split into their iterations. The "Icebox" contains all non scheduled tasks, this is where you will commonly find the "maybe" features.
Tasks can be a "Story", "Bug", "Chore" or "Release".
The primary element you will use is the "Story" type. I like to think of this as either an actual feature or a work package. I also refrain from the "As ROLE I need FEATURE as to GOAL.", because I almost always can not wrap my head around these broad categories. I have "Stories", such as "Normal Mapping", "Screen Serialisation" and such.
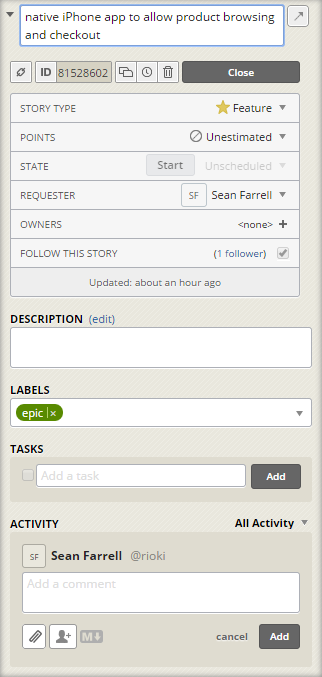
Adding "Stories" is really easy, so easy you need to be mindful not to get to carried away. Now that you have collected all your features you need to get into planing. This is done with two means, first you order the tasks by their priority. This provides a strict ordering of all your tasks, no "low", "medium", "hight" and "must", where 90% of the features end up in "must". Hard choices must be made, which feature above with other.
Here "Releases" can be created and inserted into the order of the tasks.
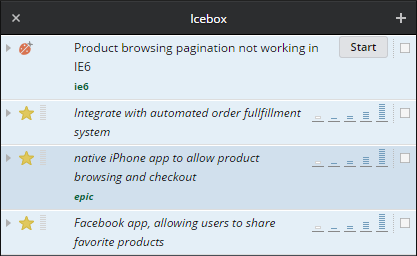
The next step is to estimate the "Stories". There are currently three schemes of doing it, Linear (0, 1, 2, 3), Powers of Two (0, 1, 2, 4, 8) and Fibonacci (0, 1, 2, 3, 5, 8). You estimate the "Stories" with some form of idealized time, use hours, days or just arbitrary weights. It actually does not matter, as long as you are consistent throughout the project. I personally prefer Powers of Two, because it is easy to say, this task is roughly double that task. If forces you to make a thought choice, is this task 8 or 4? But Fibonacci may fancy those that like to play a game [Planing Poker].
The prioritized and estimated tasks are placed into the backlog. They automatically fill up into the current iteration. This will start to give you a feeling of how long the project will take. But currently the velocity is totally wrong, since it is at a currently configured default value.
Now the work flow is simple, a developer starts to work on a "Story". He tells the team this by hitting the "Start" button. This marks the task as in progress, that is it goes from white to yellow. If the work is done, the "Story" is marked done, with "Finish" button. But since almost everybody uses something like a nightly build, the story can be marked as delivered/built by hitting the "Deliver" button. This is useful, since there is no point in testing a feature that is not yet in the hands of the tester.
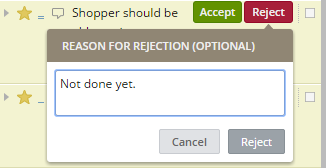
Now the tester or stakeholder can mark the features as accepted or rejected. If the feature is accepted, it is marked as accepted by being green. If the story is rejected, with a reason, work can be restarted on the "Story".
"Bugs" are like "Stories", except they are not estimated. It is assumed that they are a constant drag on the project. Similarly "Chores" are not estimated, but additionally they are not accepted by the tester/stakeholder, they are only marked as done. The idea is that "Chores" are tasks such as "setup nightly build".
"Releases" are special and only loosely fit into the task concept. The unique feature is that they can be assigned a due date. The interesting bit is that if the release happens to be scheduled behind the due date, it automatically becomes red.
The real beauty of the "Pivotal Tracker" comes after a your first iteration is over. (If don't like to think about iterations, think about weeks.) Now you know how many story points you where able to work on. The updated velocity will automatically reschedule all tasks. As time goes on your running average more accurately reflects what you and your team can do. This very accurately predicts when a feature will be done. With the releases armed with due dates, you will know how likely you will make it.
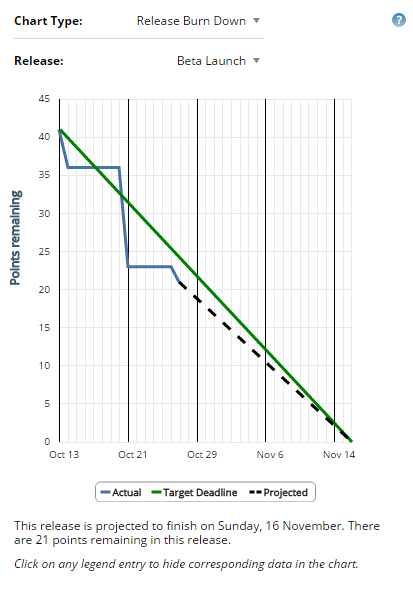
This is driven home with the charts. Especially the "Release Burn Down" shows you how you are on track to the release. (Oh wonder, the team working on the "My Sample Project" will just barely make the beta release.)
I have used Pivotal Tracker extensively for my hobby projects and it is uncannily accurate, unfortunately in many cases it also told me very accurately that I am totally in over my head.
If you happen, like me, to work in an organisation that thinks all hosted services are evil, you can use the free software fulcrum. It is basically a clone of pivotal tracker, just not as refined. The primary advantage is, you can install it on a server in your LAN.
Disclaimer: I just like Pivotal Tracker, I have nothing to do with them, except that I am a satisfied user.